oMLX 是一個開放原始碼 LLM 推論伺服器,跑在 Apple Silicon 上,透過 MLX 做推論,暴露 OpenAI 相容 API。日常使用時,從 macOS 選單列就能管理。
我們 fork 的版本最近的重點是 Native MTP——讓 Qwen 系列模型用內建的 MTP head 做多 token 預測,不需要額外的 draft model。
這次查 oMLX 的 Native MTP 為什麼慢,麻煩的不是找不到線索。
麻煩的是每條線索看起來都說得通。
MTPLX 跑同一顆 Qwen3.6 27B 可以到三十幾 tok/s,oMLX 卡在二十幾。Native MTP 明明有開,acceptance 也不是低到不能看,但速度就是上不去。這種差距最容易讓人往「一定是哪個核心沒吃到」的方向想,然後開始懷疑 sampling。
後來才發現,最要命的地方根本不在那裡。
先排除 external drafter
先把範圍講清楚,不然很容易一路查到別的方向。
官方最近也有 speculative decoding 的東西,但那條比較像另外放一顆 draft model。Qwen 這邊有趣的地方,是模型本身就有 MTP head。換句話說,不需要再找一顆小模型幫忙猜,直接用內建的 MTP head 做 native MTP。
MTPLX 做的也是這件事。
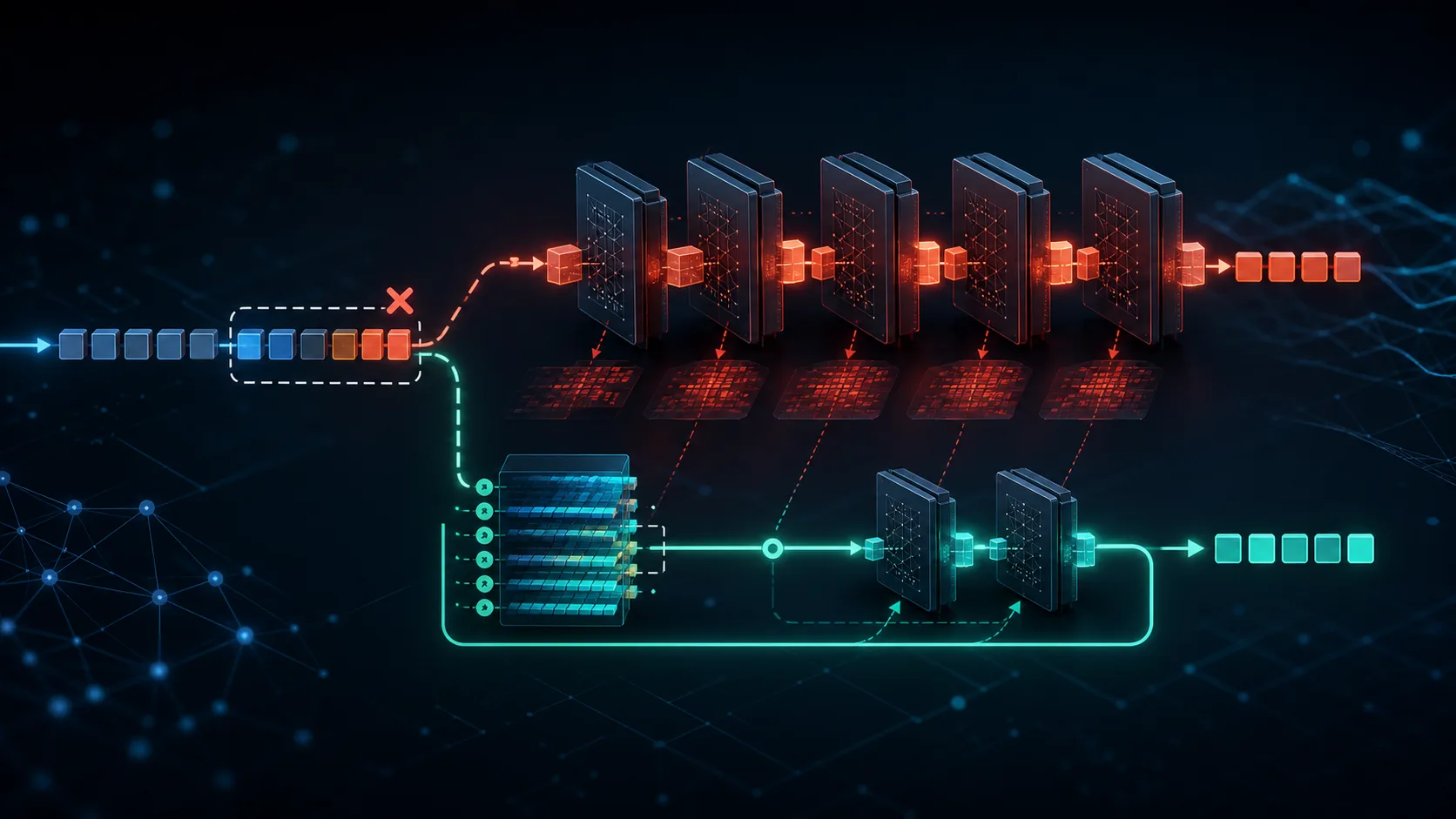
所以問題不是要不要切去 external drafter。真正值得追的是:同樣是 native MTP,為什麼 MTPLX 比 oMLX 快這麼多?
這個問題可以拆成兩件事:draft 準不準(每個 cycle 平均可以吐幾個 token),以及每個 cycle 到底花多少時間。log 裡最讓人停下來看的,是 sample time——每個 cycle 一大段時間都算在 sampling 裡。
看起來很像找到了。
sampling.py 很可疑,後來被排掉
第一步是把 top-k sparse path 打開。top_k=0 改成 top_k=20,讓 verify side 可以走 sparse distribution,不要每次都處理完整 vocab。改完有生效,log 裡看得到 sparse distribution 開始跑。
但速度沒動。
接著把 MTPLX 裡的 NumPy-based SparseDistribution、acceptance_probability、residual_sample 搬進來,取代原本比較直覺的 Python list 版本。
還是沒動。
其實這一步不算白忙。它排掉了一個很直覺的猜測:CPU acceptance walk 不是瓶頸。後來 instrumentation 拆出來,walk 只有幾毫秒,是 0.02% 那種量級。換句話說,acceptance walk 寫得再漂亮,整體速度也不會動。
那 sample time 到底在等什麼?
mx.eval 看起來很像答案,但只對一半
以下數字來自我們自己加的 profiling instrumentation,不是 oMLX 預設 log 會給的。
把 target distribution 拆開看,數字有點誇張:
tdist = 7576.5ms
tproc = 0.7ms
argp = 0.4ms
lse = 0.3ms
eval = 7565.2ms
host = 2.0ms
post = 7.5ms
幾乎所有時間都在 mx.eval。看到這種數字,第一反應就是:好,找到了。
但 MLX 是 lazy graph——很多時候 mx.eval 不是「這個 operation 本身慢」,而是「前面欠的 GPU 工作現在一起結帳」。target sparse distribution 那邊的 mx.eval,其實是在等 backbone verify graph 跑完。
MTPLX 有個 MTPLX_LAZY_VERIFY_LOGITS 設計,把 verify_hidden 和 verify_logits 的 eval 拆開。看起來很關鍵,但比對後發現,分開 eval 不讓 backbone forward 的成本消失。它只是把帳記在不同欄位。
所以 tdist/eval 很大,不代表 sparse distribution 是瓶頸。那一大段主要是 backbone verify 本來就要付的 GPU 成本,oMLX 只是把帳記在 tdist 下面。
又排掉一個。
adaptive depth 一開始太保守
這時候回頭看 tokens per cycle,發現一個比較不對勁的差異:D3 coverage。
MTPLX 幾乎每個 cycle 都 draft 到 D3,但 oMLX 的 adaptive depth 從 1 慢慢爬。有一次 log 很極端,花了 85 個 cycle 才爬到 depth 3。
這不合理。因為 per-depth acceptance 其實很接近——
D1: oMLX 約 90%,MTPLX 約 92%
D2: oMLX 約 79%,MTPLX 約 81%
D3: oMLX 約 71%,MTPLX 約 71%
模型不是不會吃 D3,是 oMLX 太晚給它 D3。
把 adaptive policy 改成從 max depth 開始,increase_after 調得更積極:
cycles: 100 -> 92
tokens/cycle: 3.00 -> 3.26
D3 drafted: 55 -> 70
tok/s: ~28.9 -> ~30.1
有改善,而且改對了。
但還是不夠,MTPLX 仍然可以跑到 37 tok/s 左右。tokens per cycle 已經比較接近,剩下的差距看起來更像 per-cycle cost。
順帶做了一個實驗:既然 D3 coverage 不夠,那乾脆固定 depth 3?
adaptive: tokens/cycle 3.26
never-decrease: tokens/cycle 3.19
fixed depth=3: tokens/cycle 3.09
反而更差。不是每個 cycle 都值得硬 draft 3 個,reject 之後塞的 D2/D3 很多都是錯的,cycles 反增。MTPLX 快,不是因為它盲目固定 depth。
partial reject 後的 replay 才是差距
最後把 cache ops 拆開,問題就亮起來了:
cache = 2622ms
full = 0.4ms / 46
reject = 2621.7ms / 53
rollback = 38.7ms
replay = 2582.8ms
cache 慢,不是慢在 rollback restore。慢的是 replay。
oMLX 在 partial reject 的時候,例如 D1 accepted、D2 rejected,會為了修正被 draft token 污染的 cache state,再重跑一次 backbone,把 accepted token replay 回去。
每次 reject 大概 48ms。53 次就是 2.58 秒。
這幾乎就是跟 MTPLX 的全部差距。
一直在追 sampling,後來才發現時間花在 cache correction。
當然,第一個實驗就是把 replay 關掉:
cache: 2622ms -> 60ms
total time: 約 -10%
acceptance: 67.9% -> 56.2%
cycles: 99 -> 112
cache 掉下來了,acceptance 也崩了。
代表 replay 不是多餘的保守操作,它在維持 GDN/SSM state 正確。拿掉之後,下一輪 MTP head 看到的 state 就偏了,draft 品質跟著掉。
不能用「關 replay」當修法,要找等價替代。
API 其實一直在旁邊
妙的是,路其實一直在旁邊。
mlx-vlm 已經有 rollback_speculative_cache 的能力,backbone forward 也有在捕捉 gdn_states。換句話說,partial reject 之後不一定要 replay backbone 才能修 GDN cache,可以直接用 speculative cache rollback 把狀態修回去。
oMLX 的 Native MTP batch generator 只是沒有把這條路接上,所以才走了昂貴的 replay。
接上之後:
cache: 2622ms -> 55ms
replay: 2583ms -> 0ms
acceptance: 67.9% -> 71.7%
tok/s: ~30 -> ~36.8
不是 approximate shortcut,不是犧牲 correctness 換速度。只是把已經存在的正確機制,接到了它本來該在的地方。
以為差不多了,然後長 context 又出事
短 prompt 看起來穩了,以為告一段落。
然後跑了一個 14k 左右的 prompt,acceptance 掉到 33.8%。不是小幅波動,是整個 MTP draft 品質垮掉。D3 drafted 只有 32/188,大部分時間走不到 depth 3。
cache 沒問題,log 很乾淨:
fb_replay=0
replay=0.0
spec_rb_count 有值
cache 約 1ms/cycle
所以只能往 position 看。
找到的點是 base_offset = state.position。
這個寫法在短 context 看起來正確,但它只追蹤 main token 的位置。Native MTP 一個 cycle 不只吐一個 token:有 accepted draft,有 bonus token,reject 時有 verify fallback token。真實序列長度一直往前走,state.position 卻只像每個 cycle 加一。
短 context 誤差小,14k、15k 之後 MTP head 拿到錯誤的 RoPE position,draft 品質就開始垮。這種 bug 很討厭,不是一開場就炸,是跑夠長之後才慢慢偏掉。
修法是改用已輸出的 token 數去推真正的 RoPE base。
accept: 33.8% -> 62.9%
D3 drafted: 32/188 -> 60/105
cycles: 188 -> 105
tok/s: 18.9 -> 22.6
22.6 不如短 prompt 漂亮,但那是 15k prompt,本來就比較重。重要的是 cycles 從 188 掉到 105,acceptance 從 30% 多回到 60% 多。
修完也補了 position diagnostics:
pos[input=1 state=37 emitted=97 rope_base=132]
這裡 input=1 不是原始 prompt 長度,是 batch generator init 當下看到的 input 長度。VLM 或 cache resume 路徑下,token buffer 可能已經被縮減,如果叫做 prompt_len,以後看 log 又會被騙一次。
改個名這件事看起來很小,但效能問題最怕的其實不是找不到瓶頸,而是欄位名字讓你以為看懂了。
VLM 也不能漏
因為這個 fork 很重要的一點是:VLM + Native MTP 不能退回 LM-only dispatch。VLMModelAdapter 要保留 mtp_forward、make_mtp_cache、return_hidden=True 這些 passthrough,不然圖片模型看起來能回答,但 vision path 或 MTP path 根本沒吃到。
測 Downloads 裡的圖片,用 Qwen3.6-27B-MTPLX-Optimized-Quality 跑,log 有看到:
VLM+MTP enabled and active
MTP path activated
fb_replay=0
spec_rb_count=25
沒有出現:
forcing LM-only dispatch, vision components ignored
RoPE offset 修完之後再跑一次,路徑仍然是通的:
accept=62.7%
fb_replay=0
spec_rb_count=10
pos[input=1 state=37 emitted=97 rope_base=132]
long-context 修正沒有把 VLM 路徑弄壞。
最後排掉的幾個嫌疑人
說起來有點無聊。
external draft model、CPU acceptance walk、NumPy sparse distribution、mx.eval、fixed depth 3,最後都被排掉了。
剩下來的問題有兩個:partial reject 後的 cache correction 太貴,長 context 下 RoPE position 會慢慢偏掉。
原本的做法其實並不是錯的。它用完整的 backbone replay 買 correctness,只是太貴。MTPLX 讓我們看到,這個 correctness 不一定要用 replay 買。更妙的是,oMLX 需要的能力其實一直在旁邊,只是 Native MTP 那條路沒有接上。
RoPE 那個更讓人挫折,因為不是 bug,是 position 欄位讓你覺得自己算對了。到夠長的 context 才開始偏,追到最後才發現餵給 MTP head 的位置根本不誠實。
這次麻煩的不是沒有線索。
是 sampling 這個嫌疑人太合理,合理到差點讓人不往下看。